

Range metadata is to lakehouses as aisle signs are to supermarkets: Without the signs hanging over the aisles, it would take shoppers extraordinarily long time to find the items they need.
I wrote a previous article introducing statistical metadata and why it's so important for SQL engines running against lakehouses. The article explained how engines get blinded and lost when such metadata is missing, and my colleague Thomas, the Database Doctor, followed up with a working example of histograms and their importance.
This is a second part in the series that talks about range metadata specifically, otherwise known as zone maps, min/max bounds or indexes, block-range indexes, skipping, micro-partition metadata etc. I'll explain what it's for, where it comes from, how big it can get, and how it's used. You'll learn about the impedance mismatch between the pipelines writing Parquet files and the tools that consume them. In the end, you'll realise that such a simple concept results in some really hard engineering problems at scale.
At Floe, we're doing hardcore engineering to solve this. Please press "Follow us" at the top of the page and register to keep up with our lakehouse antics! We won't spam you.
What's this range metadata?
Let's use the supermarket example. You're making a delicious recipe and want to buy some tastier, less processed sugar called Demerara Sugar. How do you find this product in a large store? You enter the door, walk down the aisles, and look at the overhead signs. You see one saying "Baking Needs." Sounds like it should be a match. You turn into the aisle, and see a big vertical label by a rack on the right-hand side called "Flour & Sugar." You walk over to that rack, find a couple of shelves full of sugar. On one of those shelves, sits a product called Demerara. Bingo!
This is really similar to what happens when an SQL engine goes hunting for data in a lakehouse. Each aisle is akin to a column within a Parquet file. Each rack within the aisle is akin to a "column chunk." Each shelf within the rack akin to a "page." The range metadata is akin to the overhead signs and vertical labels to show you how to find things.
Being able to find things rests on a sane supermarket layout: Products are clustered with one another and related items: Vegetables are next to other vegetables and legumes, salad dressing is nearby; baking goods are next to each other, flour and sugar are on the same shelves with yeast and baking soda nearby; etc. If products weren't clustered, the sign-posting wouldn't work and you'd have to painstakingly walk all the aisles to find what you're looking for.
A good Parquet writer will cluster data in a way that similar data are close to each other as well, so that the range metadata can help point to things and avoid the Parquet reader having to painstakingly scan the whole file.
Where is range metadata stored?
The structure of the Parquet file looks something like this (queue Yet Another Parquet Diagram):
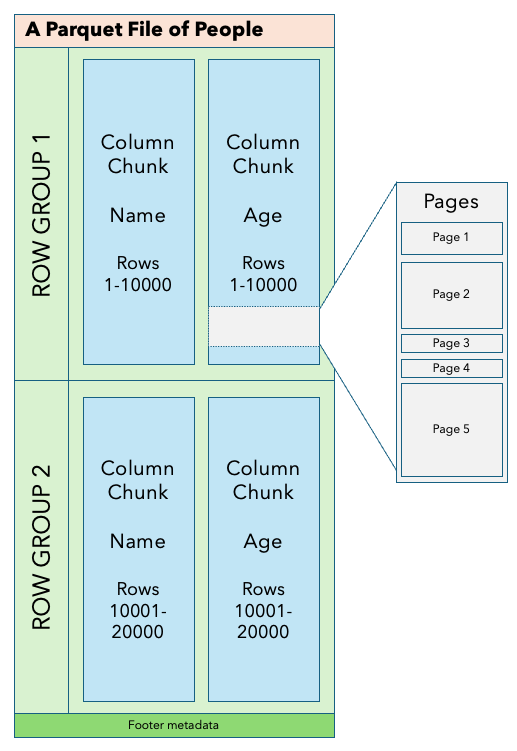
The diagram shows a simple example of a Parquet file containing two columns of data about people, Name and Age. Assuming the data within the file is well clustered, we'll probably find that people with similar names and ages are stored next to each other.
This particular file has two row groups. Each row group contains a fixed number of rows, in this case, 10,000. Within each row group are two columns of data, just like a spreadsheet, one for name and one for age. Each column chunk contains actual data pages, which are compressed, encoded names or ages. Note that page size can vary quite wildly, which makes things simpler for the writer but less optimal for the reader due to inconsistent read block sizes.
The aisle signs and labels – the range metadata – lets us find data quickly in the file. Let's look at how that works with an example: We want to find someone aged 26 years old called Quentin. Let's assume our data is clustered by age, such that all people of a similar age are located close to each other. The following diagram shows the IO path.
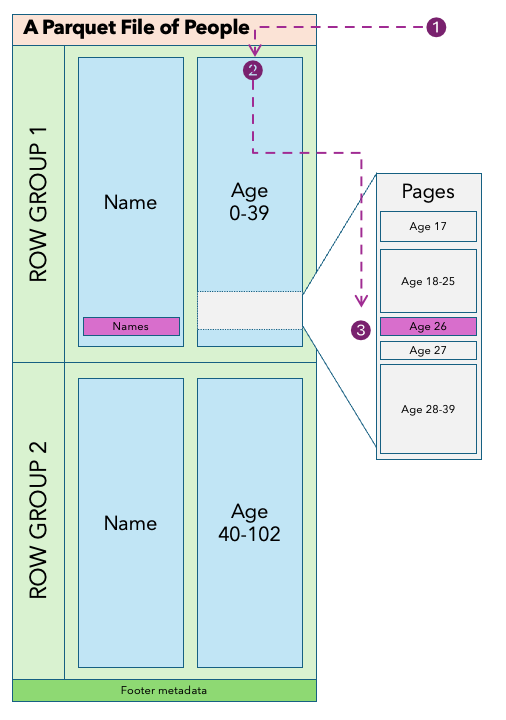
(1) The reader immediately knows which column chunk to look at for age 26. Furthermore (2) it knows which page within the column chunk has people aged 26. It can go straight to that page of data, read it (3), and read the corresponding names from the Name column chunk, returning the data required by only looking at a fraction of the table. Without the range metadata, we'd have to exhaustively read and search the whole file ("walking the whole supermarket").
Where is the range metadata?
In more recent Parquet files, range metadata is stored at the end of the file, shown as "Footer metadata" in the diagram above. The presence of range metadata is optional. It may not exist, it may exist for the column chunks only, or it may exist for every page in the file. Optional column chunk ranges within a data structure called the Footer, and optional per-page ranges are in a structure called the Page Index written next to it.
The file footer is a single, giant, serialised data structure written in a legacy encoding format called Thrift, which is a data format that lost in popularity to protobuf. It needs to be read and then deserialised in its entirety in order to pull out individual fields which is computationally expensive.
The page index is also encoded with Thrift, is optionally present for a given column chunk, and contains range metadata and null counts for every single data page within the file.
How big can it get?
One of the reasons that all these range structures are optional is that they can become enormous, particularly with very wide tables. Consider a table with thousands of columns, all of which contain string/VARCHAR data. You might think this is nuts, but I've seen it at customers!
Let's look at how the numbers scale for a wide table containing 8,000 such columns, split across 10 row groups, with an average of 4 pages per column chunk:
- Total Column Chunks: 10 row groups × 8,000 columns = 80,000
- Total Data Pages: 80,000 chunks × 4 pages = 320,000
A serialised entry for a string range takes around 200 bytes, so we end up with
- Column chunk metadata (for each row group): 80,000 column chunks * 200 = 16MB
- Page metadata: 320,000 pages * 200 = 64MB
...for a total of 80MB of range metadata. If this is a 1GB file, the range metadata overhead is 6.5%, excluding more sophisticated statistical metadata as discussed in part 1. There's not just the size overhead here, but the Thrift decode overhead as well. The overheads can be reduced by writing larger files, or by having less subdivision within files, but it's always going to be of the order of a few percent which adds up fast in terms of both space and CPU consumption for large warehouses.
Why does this matter?
With large-sized data warehouses sized in the tens of terabytes to petabytes, this range metadata becomes a "big data" problem in its own right, with metadata sizes easily scaling to terabytes or tens of terabytes, and it needs to be managed and processed as such. Many SQL engines can't deal with such large quantities of range metadata efficiently. You can't just cache all the range metadata in memory (too big), you can't just cache them all on disc in their native form (too slow to parse), you need to organise them in an index-like form where they are fast to look up, and in some cases the range metadata might not even be present anyway.
The impedance mismatch
The current approach of embedding optional range metadata in Parquet files and having the file writer choose what's needed isn't flexible enough for ad-hoc queries. This is because the data engineering teams building the ETL pipelines can't anticipate all future use cases. Ad-hoc queries, regulatory reports, in-house applications and data scientists doing feature engineering, to name a few, will look for different data in different ways.
This is why range metadata must be stored outside the Parquet files, not inside them, and what data is collected – at what granularity – must be driven by workload characteristics known to the SQL engine doing the work.
What do people do about it?
Google and Snowflake have taken a view on how to handle this problem, whereas most other SQL engines really struggle. The next article in this series will talk about the how the state of the art can be improved.
At Floe, we're committed to absolutely nailing this problem better than everyone else. We're building open source technology to make this problem disappear. Hit "Follow us" above to sign up and hear about our progress!
