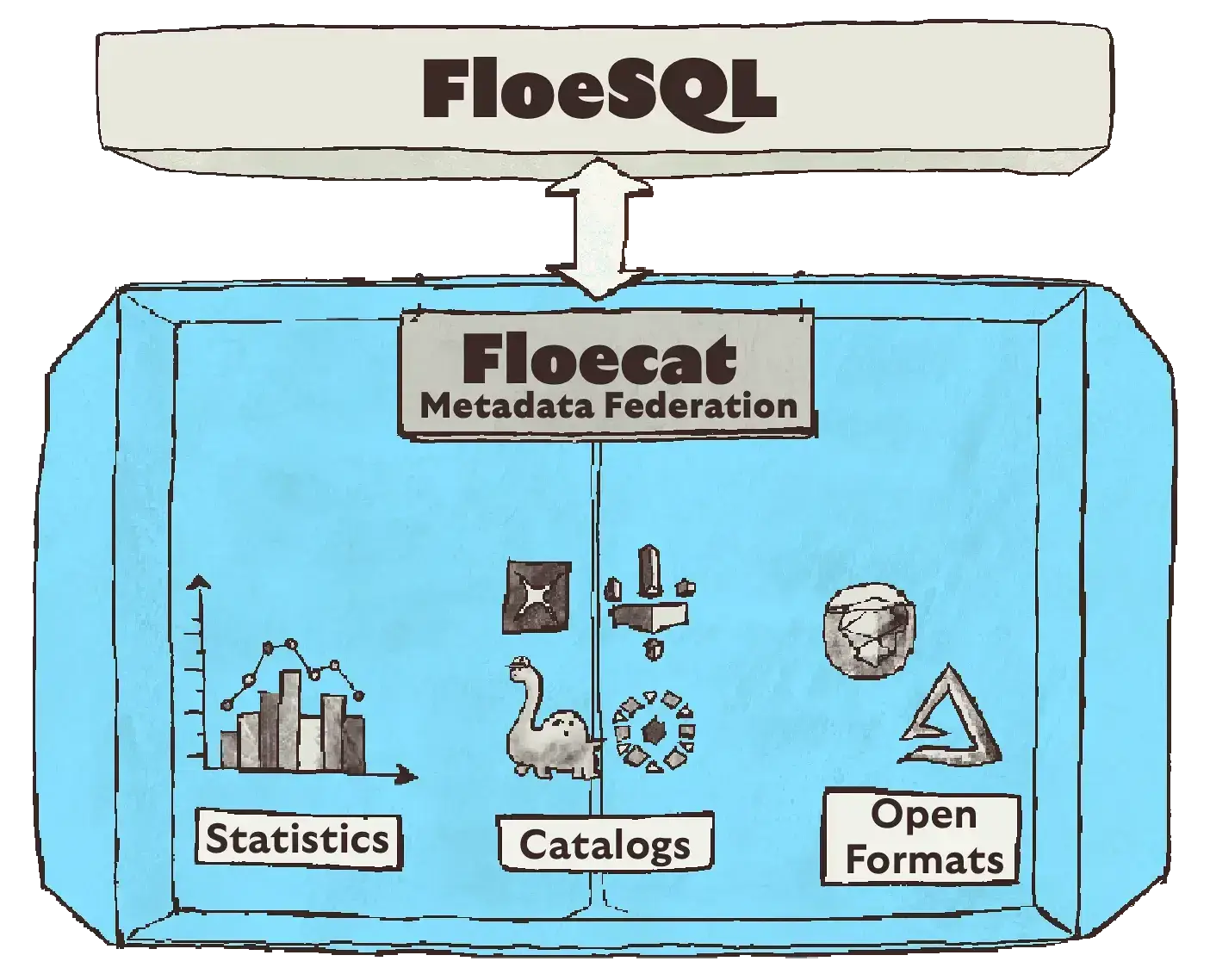
Floecat
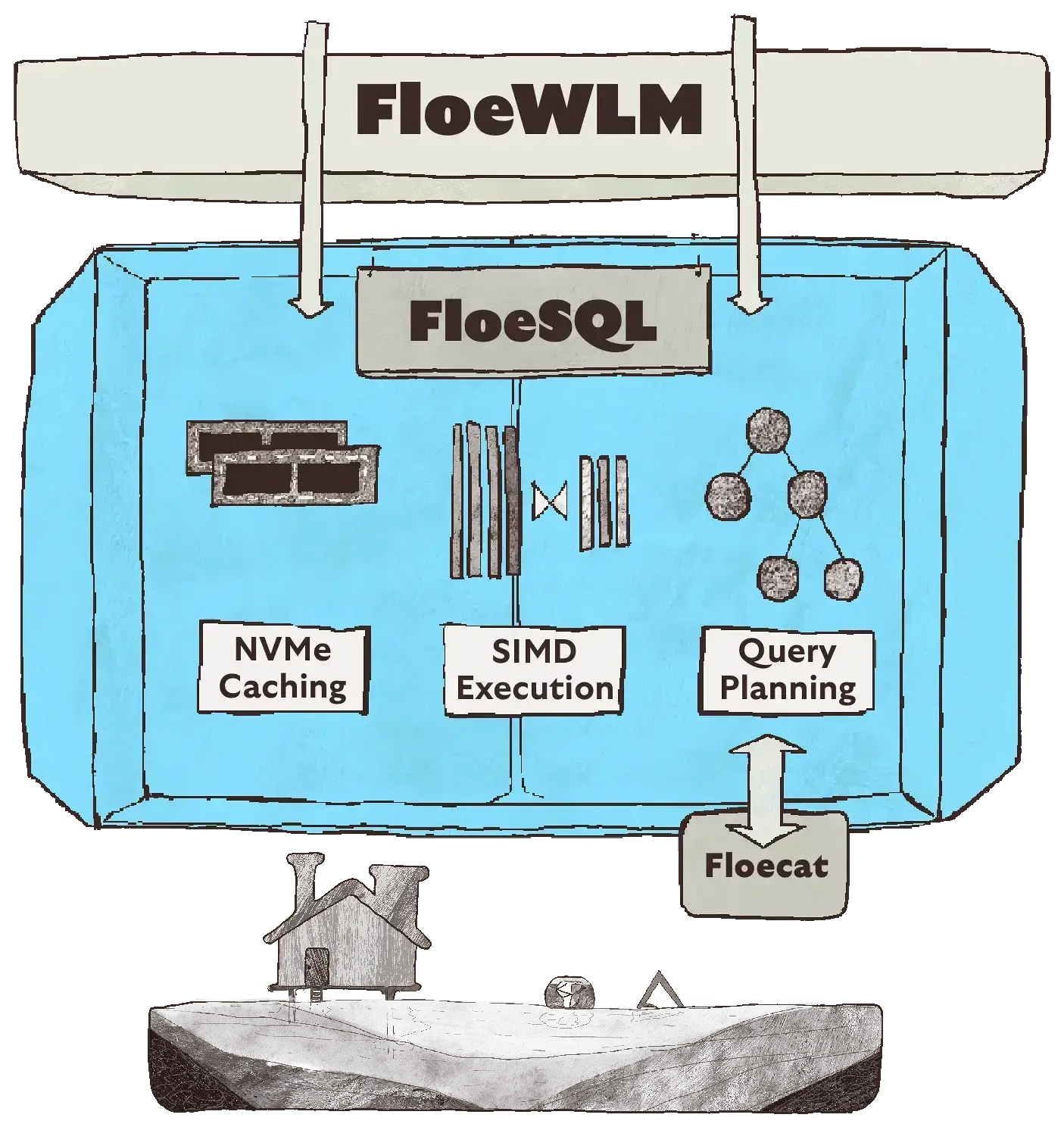
FloeSQL

FloeWLM
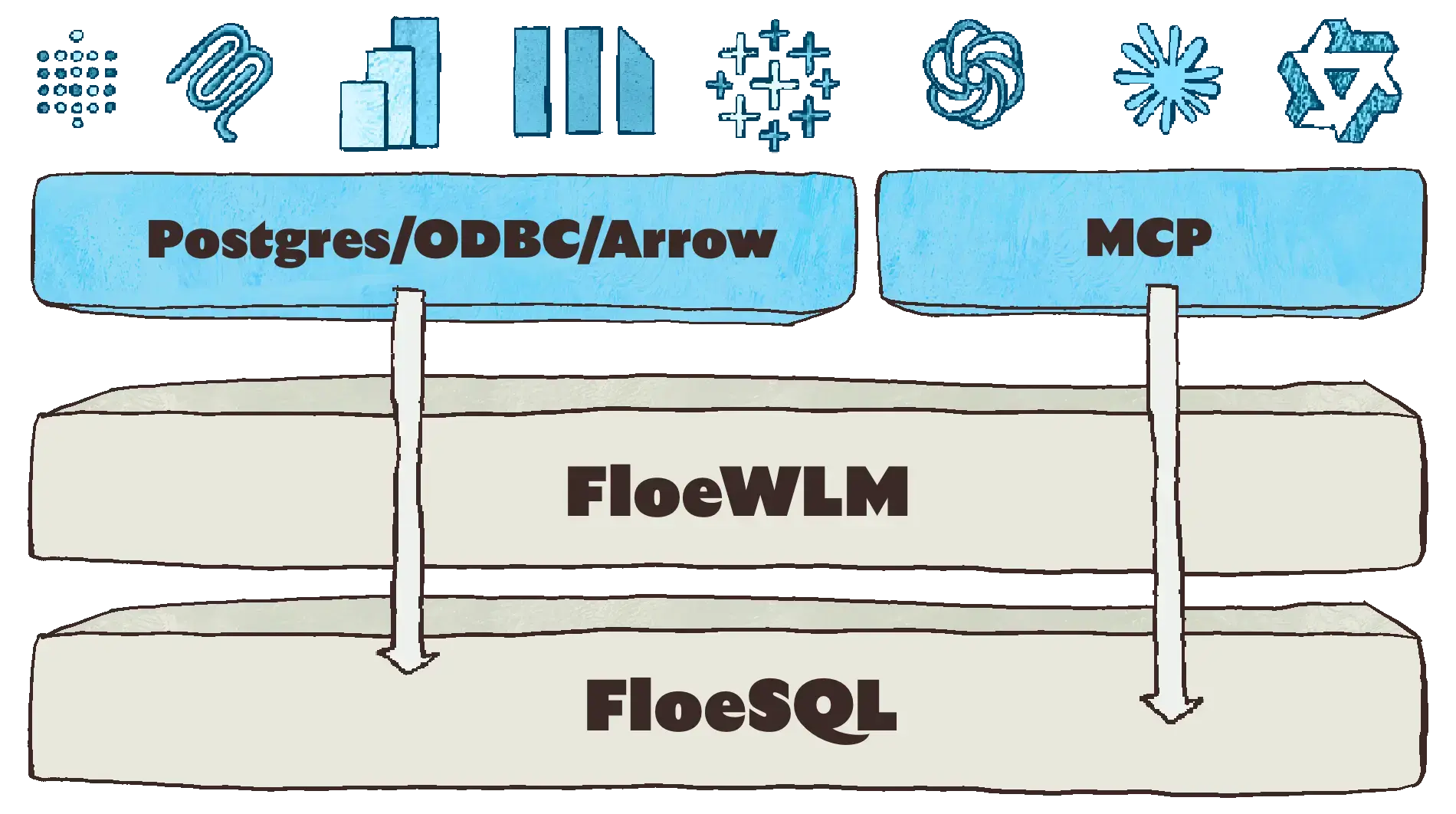
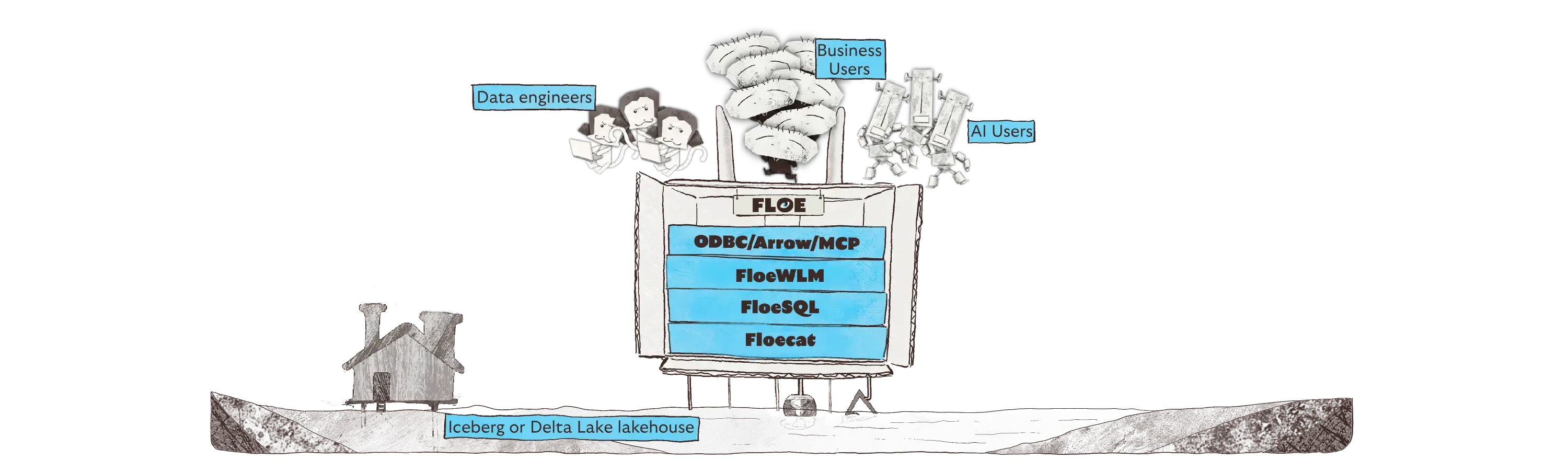
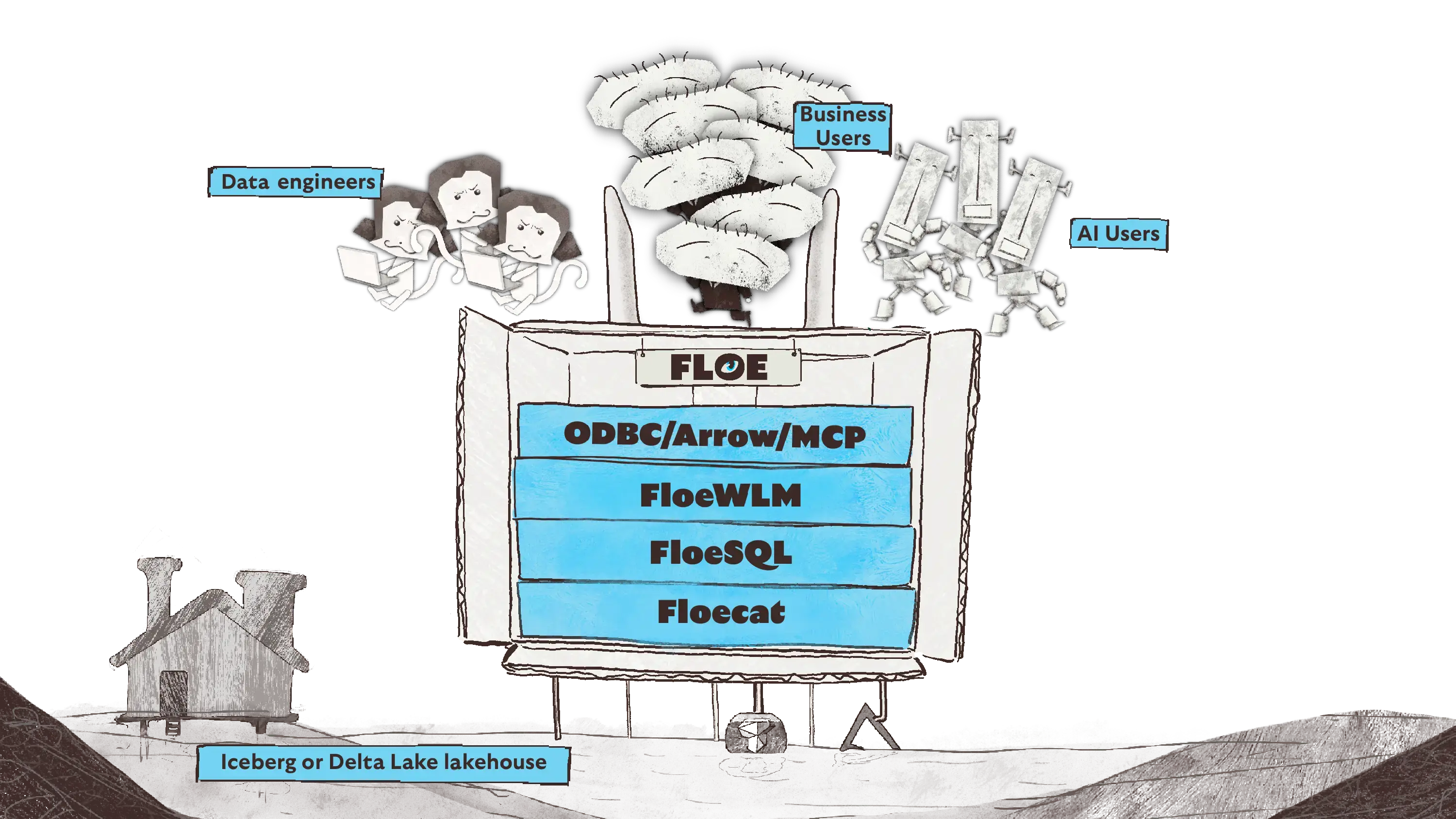
Ecosystem
